

In Work Sampling, How Will Increasing The Permissible Maximum Error Affect Sample Size?

How is Sample Size Related to Standard Fault, Power, Conviction Level, and Effect Size?
Using graphs to demonstrate the correlations
When conducting statistical analysis, especially during experimental design, ane practical issue that i cannot avert is to determine the sample size for the experiment. For example, when designing the layout of a web page, we want to know whether increasing the size of the click push button will increase the click-through probability. In this case, AB testing is an experimental method that is commonly used to solve this trouble.
Moving to the details of this experiment, y'all volition starting time determine how many users I will need to assign to the experiment group, and how many we need for the command group. The sample size is closely related to four variables, standard error of the sample, statistical power, confidence level, and the effect size of this experiment.
In this commodity, we will demonstrate their relationships with the sample size by graphs. Specifically, nosotros will discuss dissimilar scenarios with one-tail hypothesis testing.
Standard Error and Sample Size
The standard error of a statistic corresponds with the standard deviation of a parameter. Since it is near impossible to know the population distribution in most cases, we can gauge the standard deviation of a parameter by calculating the standard error of a sampling distribution. The standard error measures the dispersion of the distribution. As the sample size gets larger, the dispersion gets smaller, and the mean of the distribution is closer to the population mean (Central Limit Theory). Thus, the sample size is negatively correlated with the standard error of a sample. The graph below shows how distributions shape differently with different sample sizes:
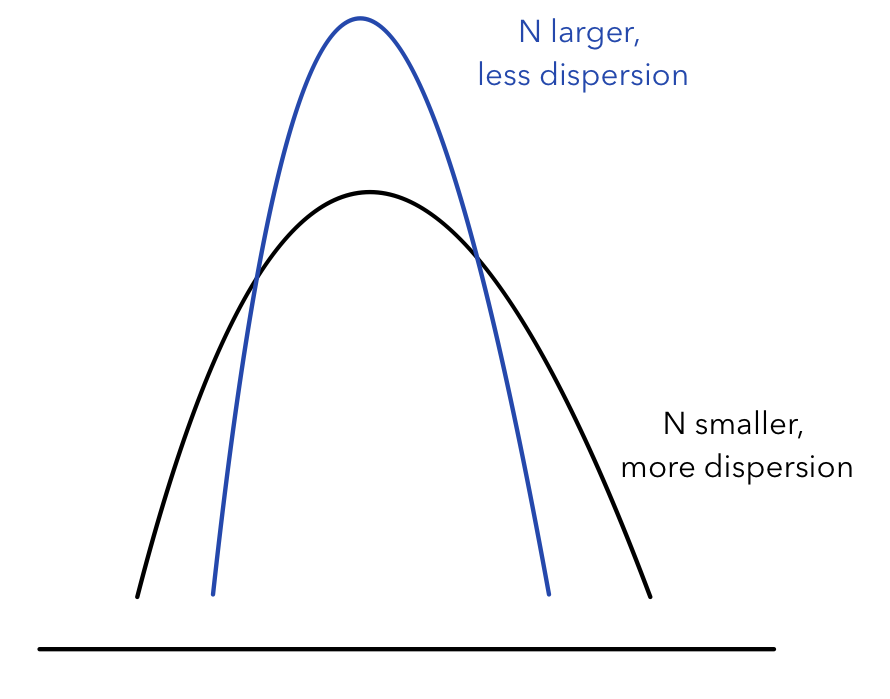
As the sample size gets larger, the sampling distribution has less dispersion and is more than centered in past the mean of the distribution, whereas the flatter curve indicates a distribution with higher dispersion since the data points are scattered across all values.
Understanding the negative correlation between sample size and standard fault help conduct the experiment. In the experiment blueprint, it is essential to constantly monitor the standard error to see if nosotros demand to increase the sample size. For example, in our previous instance, we desire to run into whether increasing the size of the bottom increases the click-through rate. The target value nosotros demand to measure out in both the command group and the experiment grouping is the click-through rate, and it is a proportion calculated equally:
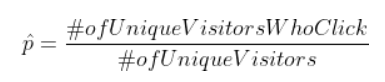
the standard error for a proportion statistic is:
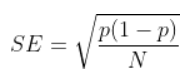
The standard mistake is at the highest when the proportion is at 0.5. When conducting the experiment, if observing p getting close to 0.5(or i-p getting close to 0.v), the standard fault is increasing. To maintain the same standard fault, we need to increment North, which is the sample size, to reduce the standard fault to its original level.
Statistical Ability and Sample Size
Statistical power is also called sensitivity. It is calculated by one- β, where β is the Type 2 fault. Higher ability means you are less likely to make a Blazon Two fault, which is failing to reject the zero hypothesis when the null hypothesis is false. As stated here:
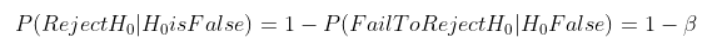
In other words, when reject region increases (credence range decreases), information technology is probable to reject. Thus, Type I error increases while Type Two error decreases. The graph beneath plots the human relationship amidst statistical power, Blazon I mistake (α) and Blazon 2 error (β) for a ane-tail hypothesis testing. After choosing a confidence level (i-α), the blue shaded area is the size of power for this particular analysis.
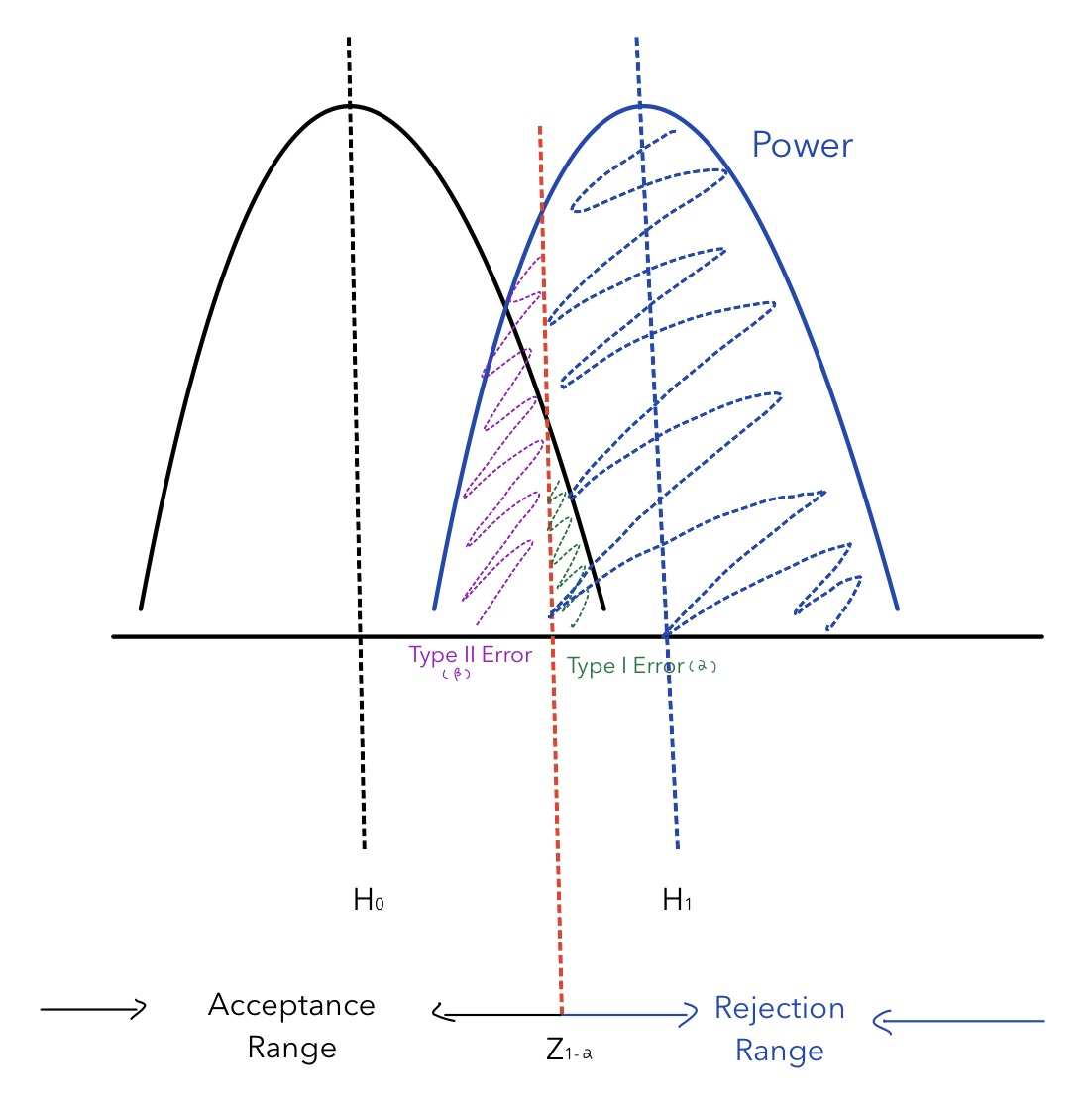
From the graph, it is obvious that statistical power (1- β) is closely related to Type 2 error (β). When β decreases, statistical ability (i- β) increases. Statistical power is besides affected to Type I error (α), when α increases, β decreases, statistical ability (1- β) increases.
The blood-red line in the centre decides the tradeoff betwixt the acceptance range and the rejection range, which determines the statistical power. How does the sample size affect the statistical power? To answer this question, we need to alter the sample size and meet how statistical power changes. Since Type I error also changes corresponded with the sample size, we need to hold information technology constant to uncover the human relationship between the sample size and the statistical power. The graph beneath illustrates their human relationship:
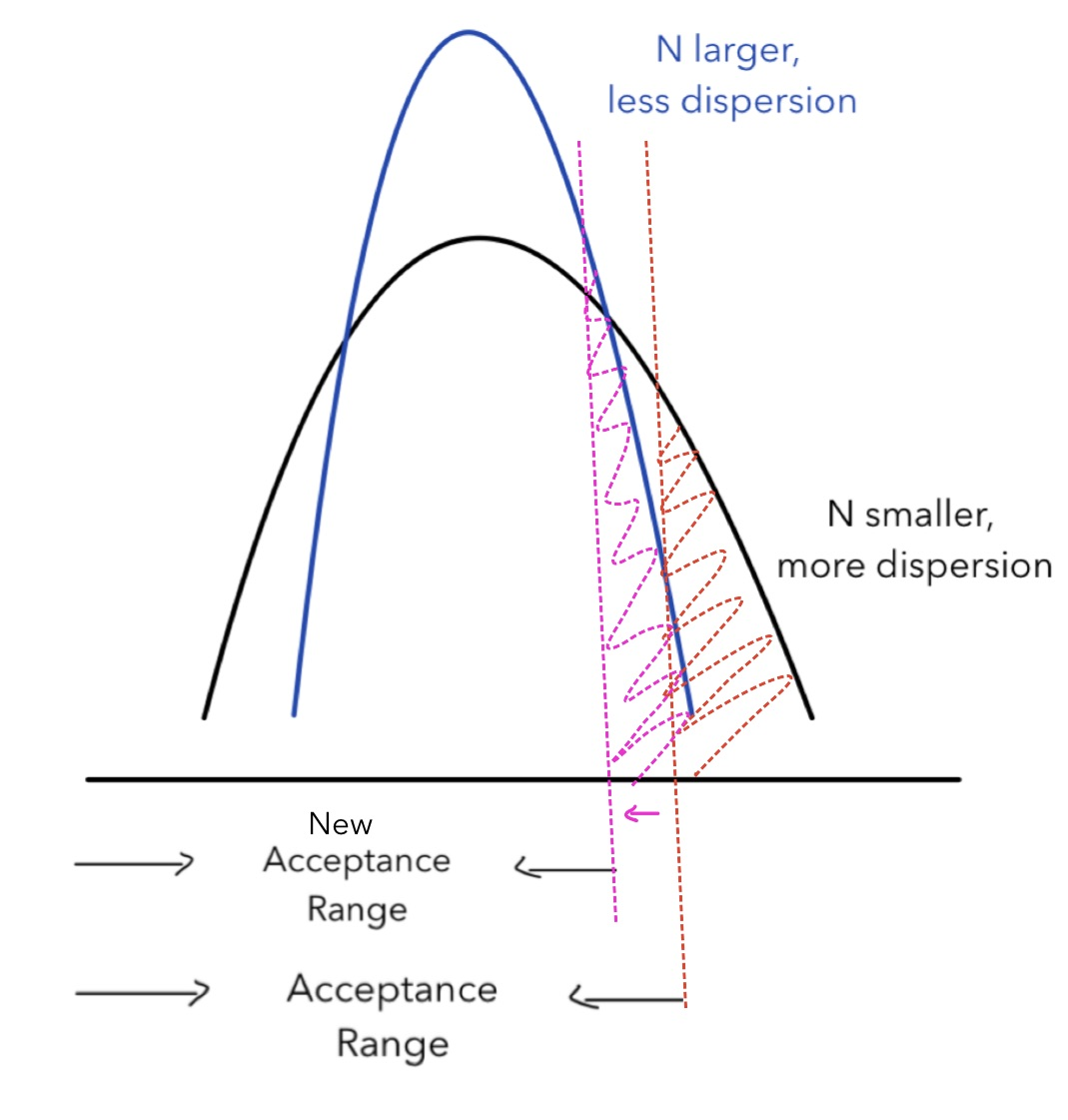
When the sample size increases, the distribution volition be more concentrated around the mean. To hold Blazon I mistake abiding, we need to decrease the disquisitional value (indicated by the red and pink vertical line). Equally a upshot, the new acceptance range is smaller. As stated above, when it is less likely to have, it is more likely to reject, and thus increases statistical ability. The graph illustrates that statistical ability and sample size have a positive correlation with each other. When the experiment requires higher statistical ability, you demand to increment the sample size.
Confidence Level and Sample Size
As stated above, the confidence level (1- α) is also closely related to the sample size, every bit shown in the graph beneath:
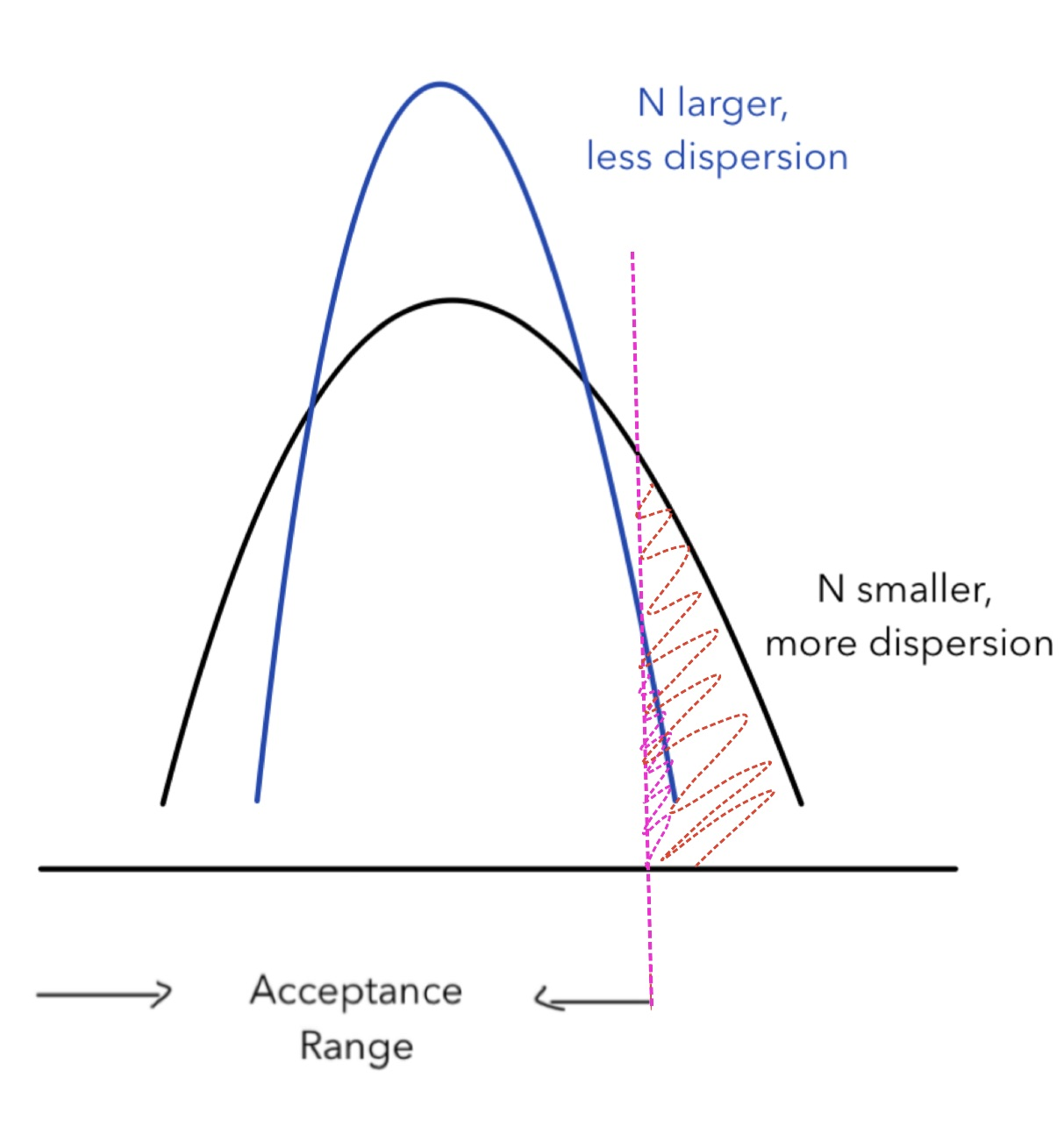
As the acceptance range keeps unchanged for both blue and black distributions, the statistical power remains unchanged. As the sample size gets larger (from blackness to bluish), the Type I error (from the ruby shade to the pink shade) gets smaller. For 1-tail hypothesis testing, when Blazon I fault decreases, the conviction level (1-α) increases. Thus, the sample size and confidence level are also positively correlated with each other.
Issue Size and Sample Size
The effect size is the applied significant level of an experiment. It is ready by the experiment designer based on applied situations. For case, when we desire to cheque whether increasing the size of the bottom in the webpage increases the click-through probabilities, we need to define how much of a difference we are measuring between the experiment group and the control group is practically meaning. Is a 0.1 difference significant enough to attract new customers or generate significant economical profits? This is the question the experiment designer has to consider. Once the effect size is set up, nosotros tin can use it to decide the sample size, and their human relationship is demonstrated in the graph below:
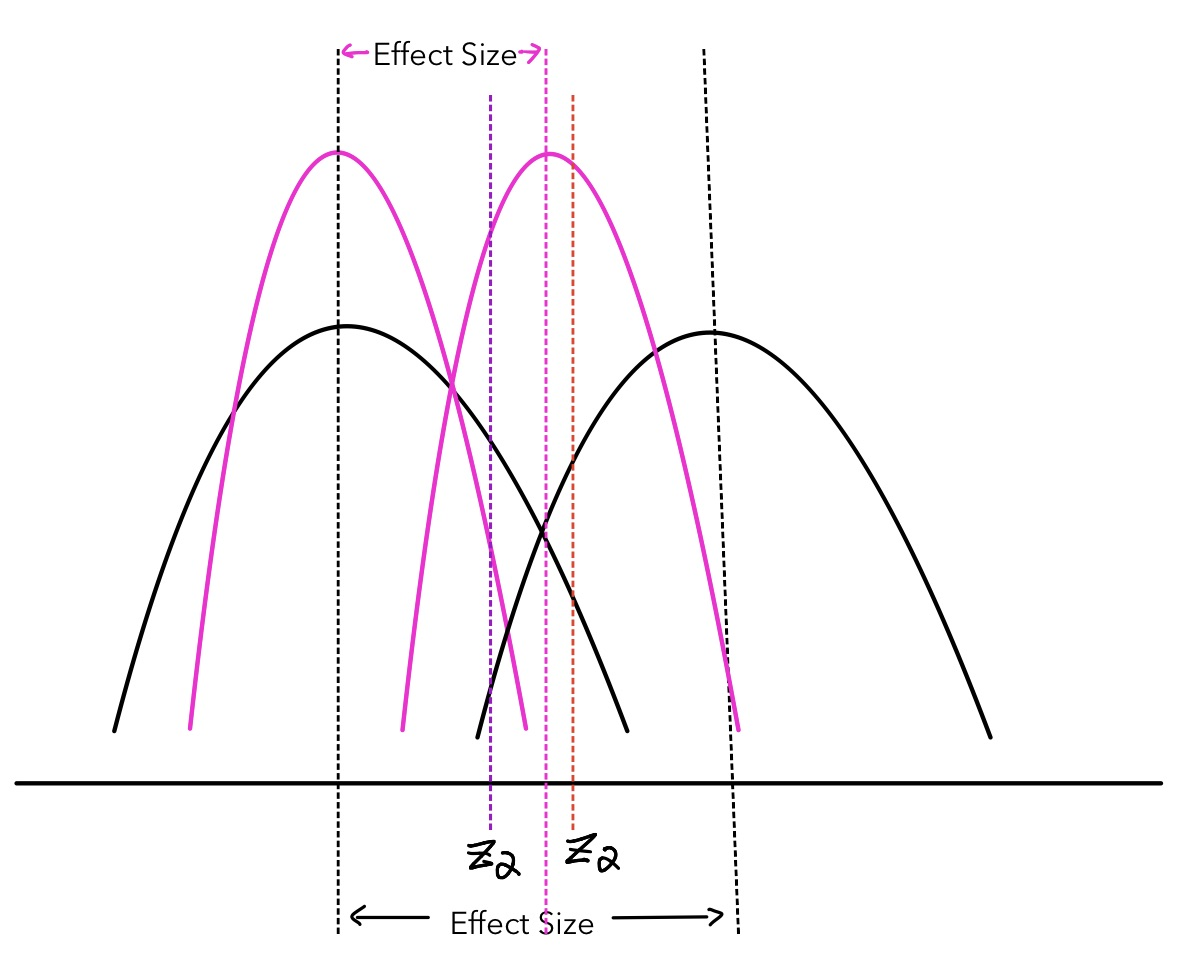
As the sample size increases, the distribution become more pointy (blackness curves to pinkish curves. To proceed the confidence level the aforementioned, nosotros need to move the critical value to the left (from the ruddy vertical line to the regal vertical line). If nosotros do not movement the culling hypothesis distribution, the statistical power will decrease. To maintain the constant power, we need to move the alternative hypothesis distribution to the left, thus the effective outcome decreases as sample size increases. Their correlation is negative.
How to interpret the correlations discussed to a higher place?
In summary, we have the following correlations betwixt the sample size and other variables:

To interpret, or better memorizing the relationship, nosotros can see that when we demand to reduce errors, for both Type I and Type Ii error, we need to increase the sample size. A larger sample size makes the sample a better representative for the population, and information technology is a improve sample to employ for statistical analysis. Equally the sample size gets larger, it is easier to detect the difference between the experiment and control grouping, even though the deviation is smaller.
How to calculate the sample size given other variables?
There are many ways to summate the sample size, and a lot of programming languages have the packages to calculate information technology for you. For case, the pwr() package in R tin do the work. Compared to knowing the exact formula, it is more important to empathise the relationships behind the formula. Hope this article helps you understand the relationships. Thank yous for reading!
Here is the listing of all my web log posts. Check them out if you are interested!

In Work Sampling, How Will Increasing The Permissible Maximum Error Affect Sample Size?,
Source: https://towardsdatascience.com/how-is-sample-size-related-to-standard-error-power-confidence-level-and-effect-size-c8ee8d904d9c
Posted by: jensenthermser56.blogspot.com
0 Response to "In Work Sampling, How Will Increasing The Permissible Maximum Error Affect Sample Size?"
Post a Comment